ตัวพิมพ์ใหญ่ ภาษาอังกฤษ: คุณกำลังดูกระทู้
ปัญหานี้สามารถเวกเตอร์ได้ด้วย SIMDสำหรับชุดอักขระ ASCII
Table of Contents
การเปรียบเทียบความเร็ว:
การทดสอบเบื้องต้นด้วย x86-64 gcc 5.2 -O3 -march=nativeบน Core2Duo (Merom) สตริงเดียวกันของอักขระ 120 ตัว (ตัวพิมพ์เล็กผสมและ ASCII ไม่ใช่ตัวพิมพ์เล็ก), แปลงเป็นลูป 40M ครั้ง (โดยไม่มีการอินไลน์ cross-file ดังนั้นคอมไพเลอร์ไม่สามารถปรับให้เหมาะสมหรือยกออกจากลูปได้) บัฟเฟอร์ต้นทางและปลายทางเดียวกันดังนั้นจึงไม่มีโอเวอร์เฮดของ Malloc หรือเอฟเฟกต์หน่วยความจำ / แคช: ข้อมูลมีความร้อนในแคช L1 ตลอดเวลาและเราใช้ CPU ล้วนๆ
-
boost::to_upper_copy<char*, std::string>(): 198.0s ใช่ Boost 1.58 บน Ubuntu 15.10 ช้ามาก ฉันทำประวัติและก้าว asm ใน debugger และมันก็แย่จริงๆ : มี dynamic_cast ของตัวแปร locale ที่เกิดขึ้นต่อตัวละคร !!! (dynamic_cast ใช้การเรียกหลายครั้งไปยัง strcmp) สิ่งนี้เกิดขึ้นกับLANG=Cและด้วยLANG=en_CA.UTF-8และมีการฉันไม่ได้ทดสอบการใช้ RangeT อื่นนอกเหนือจาก std :: string บางทีรูปแบบอื่นของการ
to_upper_copyเพิ่มประสิทธิภาพที่ดีขึ้น แต่ฉันคิดว่ามันจะnew/mallocพื้นที่สำหรับคัดลอกเสมอจึงยากที่จะทดสอบ บางทีสิ่งที่ฉันทำแตกต่างจากกรณีการใช้งานปกติและบางทีการหยุด g ++ สามารถยกการตั้งค่าโลแคลออกจากลูปต่ออักขระได้ ลูปของฉันอ่านจากstd::stringและเขียนไปยังchar dstbuf[4096]เหมาะสมสำหรับการทดสอบ -
การเรียกลูป glibc
toupper: 6.67s (ไม่ได้ตรวจสอบintผลลัพธ์สำหรับ UTF-8 หลายไบต์ที่เป็นไปได้ แต่สิ่งนี้สำคัญสำหรับตุรกี) - ASCII-only loop: 8.79s (เวอร์ชันพื้นฐานของฉันสำหรับผลลัพธ์ด้านล่าง) เห็นได้ชัดว่าการค้นหาตารางเร็วกว่า
cmovโดยที่ตารางนั้นร้อนใน L1 อยู่ดี - ASCII-only auto-vectorized: 2.51s 2.51s(120 ตัวอักษรเป็นครึ่งทางระหว่างกรณีที่เลวร้ายที่สุดและกรณีที่ดีที่สุดดูด้านล่าง)
- ASCII-vectorized ด้วยตนเองเท่านั้น: 1.35s
ดูคำถามนี้เกี่ยวกับtoupper()การช้าบน Windows เมื่อมีการตั้งค่าภาษา
ฉันตกใจที่ Boost เป็นลำดับความสำคัญช้ากว่าตัวเลือกอื่น ๆ ฉันตรวจสอบอีกครั้งว่าฉัน-O3เปิดใช้งานแล้วและแม้แต่ asm ก็ก้าวเดียวเพื่อดูว่ามันกำลังทำอะไรอยู่ มันเกือบจะเหมือนกับความเร็วด้วย clang ++ 3.8 มันมีค่าใช้จ่ายมากในวงต่อตัวละคร perf record/ reportผล (สำหรับcyclesเหตุการณ์ perf) เป็น:
32.87
%
flipcase
-
clang
-
libstdc
++.
so
.
6.0
.
21
[.]
_ZNK10__cxxabiv121__vmi_class_type_info12__do_dyncastElNS_17__class_type_info10__sub_kindEPKS1_PKvS4_S6_RNS1_16
21.90
%
flipcase
-
clang
-
libstdc
++.
so
.
6.0
.
21
[.]
__dynamic_cast
16.06
%
flipcase
-
clang
-
libc
-
2.21
.
so
[.]
__GI___strcmp_ssse3
8.16
%
flipcase
-
clang
-
libstdc
++.
so
.
6.0
.
21
[.]
_ZSt9use_facetISt5ctypeIcEERKT_RKSt6locale
7.84
%
flipcase
-
clang
-
flipcase
-
clang
-
boost
[.]
_Z16strtoupper_boostPcRKNSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEE
2.20
%
flipcase
-
clang
-
libstdc
++.
so
.
6.0
.
21
[.]
strcmp@plt
2.15
%
flipcase
-
clang
-
libstdc
++.
so
.
6.0
.
21
[.]
__dynamic_cast@plt
2.14
%
flipcase
-
clang
-
libstdc
++.
so
.
6.0
.
21
[.]
_ZNKSt6locale2id5_M_idEv
2.11
%
flipcase
-
clang
-
libstdc
++.
so
.
6.0
.
21
[.]
_ZNKSt6locale2id5_M_idEv@plt
2.08
%
flipcase
-
clang
-
libstdc
++.
so
.
6.0
.
21
[.]
_ZNKSt5ctypeIcE10do_toupperEc
2.03
%
flipcase
-
clang
-
flipcase
-
clang
-
boost
[.]
_ZSt9use_facetISt5ctypeIcEERKT_RKSt6locale@plt
0.08
%
...
Autovectorization
Gcc และ clang จะทำการวนซ้ำอัตโนมัติเวกเตอร์เมื่อทราบจำนวนการวนซ้ำก่อนลูป (นั่นคือลูปการค้นหาเช่นการใช้ C ธรรมดาstrlenจะไม่ทำให้เป็นอัตโนมัติ)
ดังนั้นสำหรับสตริงที่มีขนาดเล็กพอที่จะใส่ในแคชเราจะได้รับการเร่งความเร็วอย่างมีนัยสำคัญสำหรับสตริง ~ 128 ตัวอักษรให้ยาวstrlenก่อน สิ่งนี้ไม่จำเป็นสำหรับสตริงที่มีความยาวอย่างชัดเจน (เช่น C ++ std::string)
// char, not int, is essential: otherwise gcc unpacks to vectors of int! Huge slowdown.
char
ascii_toupper_char
(
char
c
)
{
return
(
'a'
<=
c
&&
c
<=
'z'
)
?
c
^
0x20
:
c
;
// ^ autovectorizes to PXOR: runs on more ports than paddb
}
// gcc can only auto-vectorize loops when the number of iterations is known before the first iteration. strlen gives us that
size_t
strtoupper_autovec
(
char
*
dst
,
const
char
*
src
)
{
size_t
len
=
strlen
(
src
);
for
(
size_t
i
=
0
;
i
<
len
;
++
i
)
{
dst
[
i
]
=
ascii_toupper_char
(
src
[
i
]);
// gcc does the vector range check with psubusb / pcmpeqb instead of pcmpgtb
}
return
len
;
}
libc ที่เหมาะสมจะมีประสิทธิภาพstrlenที่เร็วกว่าการวนลูปทีละครั้งดังนั้นการแยกเวกเตอร์ strlen และลูปลูปให้เร็วขึ้น
Baseline: การวนซ้ำที่ตรวจสอบการยกเลิก 0 ในทันที
คูณ 40M ซ้ำบน Core2 (Merom) 2.4GHz GCC -O3 -march=native5.2 (Ubuntu 15.10) dst != src(ดังนั้นเราจึงทำสำเนา) แต่จะไม่ทับซ้อนกัน (และไม่ใกล้เคียง) ทั้งสองอยู่ในแนวเดียวกัน
- 15 อักขระสตริง: พื้นฐาน: 1.08s autovec: 1.34 วินาที
- 16 ถ่านสตริง: พื้นฐาน: 1.16s autovec: 1.52 วินาที
- 127 อักขระสตริง: พื้นฐาน: 8.91s autovec: 2.98s // การล้างข้อมูลที่ไม่ใช่เวกเตอร์มี 15 ตัวประมวลผล
- 128 อักขระสตริง: พื้นฐาน: 9.00s autovec: 2.06 วินาที
- 129 อักขระสตริง: พื้นฐาน: 9.04s autovec: 2.07s // การล้างข้อมูลที่ไม่ใช่เวกเตอร์มี 1 อักขระที่ต้องดำเนินการ
ผลลัพธ์บางอย่างมีความแตกต่างเล็กน้อยกับเสียงดังกราว
ลูป microbenchmark ที่เรียกใช้ฟังก์ชันอยู่ในไฟล์แยกต่างหาก ไม่เช่นนั้นจะอินไลน์และstrlen()ดึงออกจากลูปและจะทำงานเร็วขึ้นอย่างมากโดยเฉพาะ สำหรับ 16 อักขระสตริง (0.187s)
นี่เป็นข้อได้เปรียบที่สำคัญที่ gcc สามารถทำให้เป็นเวกเตอร์อัตโนมัติสำหรับสถาปัตยกรรมใด ๆ ก็ได้ แต่ข้อเสียเปรียบหลักที่ทำให้ช้าลงสำหรับกรณีที่พบบ่อยของสตริงขนาดเล็ก
ดังนั้นการเร่งความเร็วครั้งยิ่งใหญ่ แต่คอมไพเลอร์อัตโนมัติ – การทำให้เป็นเวกเตอร์ไม่ได้สร้างโค้ดที่ดี สำหรับการล้างข้อมูลอักขระสูงสุดถึง 15 ตัวสุดท้าย
vectorization แบบแมนนวลที่มี SSE ภายใน:
ขึ้นอยู่กับฟังก์ชั่นตัวพิมพ์ใหญ่ – เล็กของฉันที่พลิกกรณีของตัวอักษรทุกตัว มันต้องใช้ประโยชน์จาก “เคล็ดลับเปรียบเทียบไม่ได้ลงนาม” ซึ่งคุณสามารถทำได้low < a && a <= highด้วยการเปรียบเทียบที่ไม่ได้ลงชื่อเดียวโดยช่วงการขยับเพื่อให้ค่าใด ๆ ที่น้อยกว่าการตัดค่าที่เป็นมากกว่าlow high(ใช้งานได้หากlowและhighอยู่ไม่ห่างกัน)
SSE มีเพียงการเปรียบเทียบที่ได้รับการลงนามแล้วเท่านั้น แต่เรายังคงสามารถใช้เคล็ดลับ “การเปรียบเทียบที่ไม่ได้ลงชื่อ” โดยการเลื่อนช่วงไปทางด้านล่างของช่วงที่เซ็นชื่อ: ลบ ‘a’ + 128 ดังนั้นอักขระที่เป็นตัวอักษรจะอยู่ในช่วง -128 ถึง -128 +25 (-128 + ‘z’ – ‘a’)
โปรดทราบว่าการเพิ่ม 128 และการลบ 128 เป็นสิ่งเดียวกันสำหรับจำนวนเต็ม 8 บิต ไม่มีที่ใดที่จะนำติดตัวไปได้ดังนั้นจึงเป็นเพียงแค่แฮคเกอร์
#include
<immintrin.h>
__m128i upcase_si128
(
__m128i src
)
{
// The above 2 paragraphs were comments here
__m128i rangeshift
=
_mm_sub_epi8
(
src
,
_mm_set1_epi8
(
'a'
+
128
));
__m128i nomodify
=
_mm_cmpgt_epi8
(
rangeshift
,
_mm_set1_epi8
(-
128
+
25
));
// 0:lower case -1:anything else (upper case or non-alphabetic). 25 = 'z' - 'a'
__m128i flip
=
_mm_andnot_si128
(
nomodify
,
_mm_set1_epi8
(
0x20
));
// 0x20:lcase 0:non-lcase
// just mask the XOR-mask so elements are XORed with 0 instead of 0x20
return
_mm_xor_si128
(
src
,
flip
);
// it's easier to xor with 0x20 or 0 than to AND with ~0x20 or 0xFF
}
เนื่องจากฟังก์ชั่นนี้ใช้งานได้กับเวกเตอร์หนึ่งตัวเราสามารถเรียกมันเป็นลูปเพื่อประมวลผลสตริงทั้งหมด เนื่องจากเรากำหนดเป้าหมายไปที่ SSE2 แล้วเราสามารถทำการตรวจสอบจุดสิ้นสุดของสตริงแบบเวกเตอร์ได้ในเวลาเดียวกัน
นอกจากนี้เรายังสามารถทำได้ดีกว่าสำหรับ “การล้างข้อมูล” ของไบต์สูงสุด 15 ไบต์สุดท้ายที่เหลือหลังจากทำเวกเตอร์ 16B: ปลอกด้านบนเป็น idempotent ดังนั้นการประมวลผลอินพุตไบต์บางครั้งจึงไม่เป็นผล เราทำการโหลดที่ไม่ตรงแนวของ 16B สุดท้ายของแหล่งที่มาและเก็บไว้ในบัฟเฟอร์ปลายทางทับซ้อนที่เก็บ 16B สุดท้ายจากลูป
ครั้งเดียวที่ใช้งานไม่ได้คือเมื่อสตริงทั้งหมดมีค่าต่ำกว่า 16B: แม้ว่าdst=srcการอ่าน – แก้ไข – เขียนที่ไม่ใช่อะตอมไม่ใช่สิ่งเดียวกับที่ไม่ได้สัมผัสบางไบต์เลยและสามารถทำลายรหัสแบบมัลติเธรดได้
เรามีสเกลาร์วนรอบสำหรับสิ่งนั้นและเพื่อให้ได้srcแนวเดียวกัน เนื่องจากเราไม่ทราบว่าจุดสิ้นสุดของ 0 จะเป็นอย่างไรการโหลดที่ไม่ได้แนวจากsrcอาจข้ามไปยังหน้าถัดไปและ segfault หากเราต้องการไบต์ใด ๆ ในก้อนขนาด 16B ที่เรียงกันจะปลอดภัยเสมอที่จะโหลดก้อนขนาด 16B ที่เรียงกันทั้งหมด
แหล่งที่มาเต็มรูปแบบ: ในส่วนสำคัญ GitHub
// FIXME: doesn't always copy the terminating 0.
// microbenchmarks are for this version of the code (with _mm_store in the loop, instead of storeu, for Merom).
size_t
strtoupper_sse2
(
char
*
dst
,
const
char
*
src_begin
)
{
const
char
*
src
=
src_begin
;
// scalar until the src pointer is aligned
while
(
(
0xf
&
(
uintptr_t
)
src
)
&&
*
src
)
{
*(
dst
++)
=
ascii_toupper
(*(
src
++));
}
if
(!*
src
)
return
src
-
src_begin
;
// current position (p) is now 16B-aligned, and we're not at the end
int
zero_positions
;
do
{
__m128i sv
=
_mm_load_si128
(
(
const
__m128i
*)
src
);
// TODO: SSE4.2 PCMPISTRI or PCMPISTRM version to combine the lower-case and '\0' detection?
__m128i nullcheck
=
_mm_cmpeq_epi8
(
_mm_setzero_si128
(),
sv
);
zero_positions
=
_mm_movemask_epi8
(
nullcheck
);
// TODO: unroll so the null-byte check takes less overhead
if
(
zero_positions
)
break
;
__m128i upcased
=
upcase_si128
(
sv
);
// doing this before the loop break lets gcc realize that the constants are still in registers for the unaligned cleanup version. But it leads to more wasted insns in the early-out case
_mm_storeu_si128
((
__m128i
*)
dst
,
upcased
);
//_mm_store_si128((__m128i*)dst, upcased); // for testing on CPUs where storeu is slow
src
+=
16
;
dst
+=
16
;
}
while
(
1
);
// handle the last few bytes. Options: scalar loop, masked store, or unaligned 16B.
// rewriting some bytes beyond the end of the string would be easy,
// but doing a non-atomic read-modify-write outside of the string is not safe.
// Upcasing is idempotent, so unaligned potentially-overlapping is a good option.
unsigned
int
cleanup_bytes
=
ffs
(
zero_positions
)
-
1
;
// excluding the trailing null
const
char
*
last_byte
=
src
+
cleanup_bytes
;
// points at the terminating '\0'
// FIXME: copy the terminating 0 when we end at an aligned vector boundary
// optionally special-case cleanup_bytes == 15: final aligned vector can be used.
if
(
cleanup_bytes
>
0
)
{
if
(
last_byte
-
src_begin
>=
16
)
{
// if src==dest, this load overlaps with the last store: store-forwarding stall. Hopefully OOO execution hides it
__m128i sv
=
_mm_loadu_si128
(
(
const
__m128i
*)(
last_byte
-
15
)
);
// includes the \0
_mm_storeu_si128
((
__m128i
*)(
dst
+
cleanup_bytes
-
15
),
upcase_si128
(
sv
));
}
else
{
// whole string less than 16B
// if this is common, try 64b or even 32b cleanup with movq / movd and upcase_si128
#if 1
for
(
unsigned
int
i
=
0
;
i
<=
cleanup_bytes
;
++
i
)
{
dst
[
i
]
=
ascii_toupper
(
src
[
i
]);
}
#else
// gcc stupidly auto-vectorizes this, resulting in huge code bloat, but no measurable slowdown because it never runs
for
(
int
i
=
cleanup_bytes
-
1
;
i
>=
0
;
--
i
)
{
dst
[
i
]
=
ascii_toupper
(
src
[
i
]);
}
#endif
}
}
return
last_byte
-
src_begin
;
}
คูณ 40M ซ้ำบน Core2 (Merom) 2.4GHz GCC -O3 -march=native5.2 (Ubuntu 15.10) dst != src(ดังนั้นเราจึงทำสำเนา) แต่จะไม่ทับซ้อนกัน (และไม่ใกล้เคียง) ทั้งสองอยู่ในแนวเดียวกัน
- 15 อักขระสตริง: พื้นฐาน: 1.08s autovec: 1.34 วินาที คู่มือ: 1.29 วินาที
- 16 ถ่านสตริง: พื้นฐาน: 1.16s autovec: 1.52 วินาที คู่มือ: 0.335 วินาที
- 31 char string: manual: 0.479s
- 127 อักขระสตริง: พื้นฐาน: 8.91s autovec: 2.98s คู่มือ: 0.925 วินาที
- 128 อักขระสตริง: พื้นฐาน: 9.00s autovec: 2.06 วินาที คู่มือ: 0.931 วินาที
- 129 อักขระสตริง: พื้นฐาน: 9.04s autovec: 2.07s คู่มือ: 1.02 วินาที
(หมดเวลาจริง_mm_storeในวงไม่_mm_storeuเพราะ storeu ช้าลงใน Merom แม้ว่าที่อยู่จะถูกจัดตำแหน่งมันใช้ได้กับ Nehalem และใหม่กว่าฉันยังทิ้งรหัสตามเดิมไว้ตอนนี้แทนที่จะแก้ไขความล้มเหลวในการคัดลอก 0 ที่ยุติในบางกรณีเพราะฉันไม่ต้องการเวลาทุกอย่างอีกครั้ง)
ดังนั้นสำหรับสตริงสั้น ๆ ที่ยาวกว่า 16B จะเร็วกว่าการปรับเวกเตอร์อัตโนมัติอย่างมาก ความยาวหนึ่งน้อยกว่าความกว้างเวกเตอร์ไม่แสดงปัญหา พวกเขาอาจมีปัญหาเมื่อใช้งานในสถานที่เนื่องจากแผงลอยส่งต่อร้านค้า (แต่โปรดทราบว่าการประมวลผลเอาต์พุตของเราเองนั้นยังดีกว่าอินพุตดั้งเดิมเพราะ toupper เป็น idempotent)
มีขอบเขตจำนวนมากสำหรับการปรับจูนนี้สำหรับการใช้งานที่แตกต่างกันขึ้นอยู่กับสิ่งที่ต้องการโดยรอบโค้ดและสถาปัตยกรรมไมโครเป้าหมาย รับคอมไพเลอร์ที่จะปล่อยรหัสที่ดีสำหรับส่วนการทำความสะอาดเป็นเรื่องยุ่งยาก การใช้ffs(3) (ซึ่งคอมไพล์กับ bsf หรือ tzcnt บน x86) ดูเหมือนว่าจะดี แต่เห็นได้ชัดว่าบิตต้องคิดใหม่เนื่องจากฉันสังเกตเห็นข้อผิดพลาดหลังจากเขียนคำตอบส่วนใหญ่ (ดูความคิดเห็น FIXME)
speedups เวกเตอร์สำหรับสตริงแม้มีขนาดเล็กสามารถรับกับmovqหรือmovdโหลด / ร้านค้า ปรับแต่งตามความจำเป็นสำหรับการใช้งานของคุณ
UTF-8:
เราสามารถตรวจจับได้เมื่อเวกเตอร์ของเรามีไบต์ใด ๆ ที่มีชุดบิตสูงและในกรณีนั้นกลับไปเป็นวนรอบสเกลาร์ UTF-8 ที่ทราบสำหรับเวกเตอร์นั้น dstจุดสามารถล่วงหน้าตามจำนวนเงินที่แตกต่างจากsrcตัวชี้ แต่เมื่อเราได้รับกลับไปชิดsrcชี้เราจะยังคงเป็นเพียงทำร้านค้าเวกเตอร์ unaligned dstไป
สำหรับข้อความที่เป็น UTF-8 แต่ส่วนใหญ่ประกอบด้วยชุดย่อย ASCII ของ UTF-8 สิ่งนี้อาจดี: ประสิทธิภาพสูงในกรณีทั่วไปที่มีพฤติกรรมที่ถูกต้องในทุกกรณี เมื่อมี non-ASCII จำนวนมากมันอาจจะแย่กว่าการอยู่ใน scal วน UTF-8 ที่รู้อยู่ตลอดเวลา
การทำให้ภาษาอังกฤษเร็วขึ้นด้วยค่าใช้จ่ายของภาษาอื่นไม่ใช่การตัดสินใจในอนาคตหากข้อเสียมีความสำคัญ
รู้สถานที่:
ในโลแคลภาษาตุรกี ( tr_TR) ผลที่ถูกต้องtoupper('i')คือ'İ'(U0130) ไม่ใช่'I'(ASCII ธรรมดา) ดูความคิดเห็นของ Martin Bonnerเกี่ยวกับคำถามtolower()ว่า Windows ทำงานช้า
นอกจากนี้เรายังสามารถตรวจสอบรายการยกเว้นและย้อนกลับไปยังเซนต์คิตส์และเนวิสที่นั่นเช่นอักขระอินพุตหลายไบต์ UTF8
ด้วยความซับซ้อนที่มากนี้ SSE4.2 PCMPISTRMหรือบางสิ่งบางอย่างอาจทำให้เช็คของเรามากมายในครั้งเดียว
[NEW] หลักการใช้ Capital Letter ง่ายๆ 5 ข้อ | ตัวพิมพ์ใหญ่ ภาษาอังกฤษ – NATAVIGUIDES
เวลาเขียนภาษาอังกฤษ เคยสับสนไหมครับว่า เอ…คำนี้ต้องใช้ capital letter (ตัวอักษรใหญ่) ไหมนะ เช่น จะเขียน Mother’s Day หรือ mother’s day ดี หรือระหว่าง Oxford Street กับ Oxford street เขียนแบบไหนถึงจะถูกต้อง บทความนี้จะทำให้คุณสับสนมากขึ้น เอ้ย! หายสับสนว่ากรณีไหนบ้างต้องใช้ capital letter กรณีไหนบ้างไม่ต้องใช้
การใช้ capital letter ให้ถูกต้องนั้นมีความสำคัญเป็นอย่างมาก แม้ว่าเราอาจจะไม่ได้ใส่ใจเวลาพิมพ์แชทกับเพื่อนหรือคนในครอบครัว แต่เวลาเขียนจดหมาย บทความ หรืองานเขียนใดๆ ที่เป็นทางการ การใช้ capital letter ที่ไม่ถูกต้องอาจทำให้เราดูไม่เป็นมืออาชีพ หรืออาจทำให้สื่อสารผิดพลาดได้

การใช้ capital letter มีหลักง่ายๆ 5 ข้อ คือ
1. ใช้ capital letter เมื่อขึ้นต้นประโยค
นั่นคือ ตัวอักษรแรกของคำแรกในประโยคจะต้องเป็นตัวอักษรใหญ่ เช่น
- She watched Game of Thrones with me last night. (เธอดูมหาศึกชิงบัลลังก์กับฉันเมื่อคืนนี้)
- I met a girl this morning. Her name was Arya. (ฉันพบเด็กสาวคนหนึ่งเมื่อเช้านี้ เธอชื่ออาร์ยา)
แต่สำหรับประโยคที่ตามหลังเครื่องหมาย colon * (:) และ semicolon (;) ไม่ต้องใช้ capital letter เช่น
- He got what he deserved: he was dumped. (เขาได้รับในสิ่งที่สมควรได้ เขาถูกทิ้ง)
- Some people write with a pen; others write with a pencil. (บางคนเขียนด้วยปากกา แต่บางคนเขียนด้วยดินสอ)
* ยกเว้นภาษาอังกฤษแบบอเมริกัน ให้ใช้ capital letter เมื่อขึ้นต้นประโยคหลังเครื่องหมาย colon
He got what he deserved: He was dumped.
ข้อยกเว้นอีกข้อคือคำว่า I (ฉัน) ต้องใช้ตัวอักษรใหญ่เท่านั้นไม่ว่าจะอยู่ส่วนไหนของประโยค เช่น
Do I know you? (ฉันรู้จักคุณเหรอ)
2. คำนามเฉพาะ (proper noun)
ให้ใช้ capital letter เมื่อเขียนคำนามเฉพาะ คำนามเฉพาะมีอยู่ด้วยกันหลายประเภท ได้แก่
- ชื่อ นามสกุล และคำนำหน้าชื่อ เช่น Jon Snow (จอน สโนว์), Mr Potter (คุณพอตเตอร์), Professor Dumbledore (ศาสตราจารย์ดัมเบิลดอร์)
- เดือนและวัน เช่น Sunday (วันอาทิตย์), Friday (วันศุกร์), February (เดือนกุมภาพันธ์), December (เดือนธันวาคม)
- ฤดู ได้แก่ Spring (ฤดูใบไม้ผลิ), Summer (ฤดูร้อน), Autumn/Fall (ฤดูใบไม้ร่วง), Winter (ฤดูหนาว)
- วันสำคัญ เช่น Mother’s Day (วันแม่), Christmas (วันคริสต์มาส), New Year’s Day (วันปีใหม่), Valentine’s Day (วันวาเลนไทน์)
- ชื่อประเทศ เช่น Thailand (ประเทศไทย), England (ประเทศอังกฤษ), Scotland (ประเทศสก็อตแลนด์), France (ประเทศฝรั่งเศส)
- ชื่อรัฐ ชื่อเมือง และชื่อเขตการปกครองต่างๆ เช่น California (รัฐแคลิฟอร์เนีย), London (กรุงลอนดอน), Edinburgh (กรุงเอดินบะระ), Oxfordshire (มณฑลอ๊อกซฟอร์ดเชอร์)
- ชื่อแม่น้ำ ทะเล ทะเลสาบ และมหาสมุทร เช่น the Thames (แม่น้ำเทมส์), the Mekong (แม่น้ำโขง), the Pacific (มหาสมุทรแปซิฟิก)
- ชื่อพื้นที่ทางภูมิศาสตร์ต่างๆ เช่น the Bosphorus (ช่องแคบบอสฟอรัส), the Himalayas (เทือกเขาหิมาลัย), the Alps (เทือกเขาแอลป์), the Sahara (ทะเลทรายสะฮารา)
- ชื่อสัญชาติและภาษา เช่น Thai (คนไทย ภาษาไทย), English (คนอังกฤษ ภาษาอังกฤษ), Italian (คนอิตาเลียน ภาษาอิตาเลียน)
- ชื่อถนน ตึก สวน และสิ่งก่อสร้างต่างๆ เช่น the Empire State Building (ตึกเอ็มไพร์สเตต), Central Park (สวนสาธารณะเซ็นทรัลพาร์ค), the Eiffel Tower (หอไอเฟล)
3. ชื่อเรื่อง เช่น ชื่อหนังสือ ชื่อบทความ
ใช้ตัวอักษรใหญ่ขึ้นต้นคำประเภท noun (คำนาม), verb (คำกริยา), adjective (คำคุณศัพท์), adverb (คำวิเศษณ์), subordinating conjunction (เช่น because, that, as) แต่ไม่ต้องใช้ตัวอักษรใหญ่ขึ้นต้นคำประเภท article (คำนำหน้านาม ได้แก่ a, and, the), preposition (คำบุพบท เช่น in, on, at), coordinating conjunction (เช่น for, and, but, or) ตัวอย่างเช่น
“Harry Potter and the Cursed Child” (แฮร์รี่ พอตเตอร์ กับเด็กต้องคำสาป)
จากตัวอย่างจะเห็นว่าทุกคำยกเว้น and และ the ขึ้นต้นด้วยตัวอักษรใหญ่
อย่างไรก็ตามบทความในปัจจุบันเริ่มนิยมใช้ capital letter แค่คำแรกของชื่อเท่านั้น เช่น “Energy solutions for a sustainable world”
นอกจากนี้ตามปกหนังสือหรือโปสเตอร์ภาพยนตร์ ชื่อเรื่องจะถูกเขียนเป็นตัวอักษรใหญ่ทั้งหมด เช่น “HARRY POTTER AND THE CURSED CHILD” ซึ่งการเขียนแบบนี้ก็ไม่ผิดอะไร แต่ถ้าเราไปเขียนชื่อเรื่องที่อื่น แนะนำให้เขียนตามหลักการเขียนชื่อเรื่องที่กล่าวมา
4. คำย่อต่างๆ
คำย่อต่างๆ โดยเฉพาะคำย่อชื่อนิยมใช้ capital letter ตัวอย่างเช่น
UN = United Nations (สหประชาชาติ)
NATO = North Atlantic Treaty Organization (องค์การสนธิสัญญาแอตแลนติกเหนือ)
ASEAN = Association of Southeast Asian Nations (สมาคมประชาชาติแห่งเอเชียตะวันออกเฉียงใต้)
แต่ก็ไม่ใช่ว่าคำย่อทุกคำจะใช้ตัวอักษรใหญ่ ตัวอย่างคำยกเว้น เช่น cm = centimetre/centimeter (เซนติเมตร) หรือบางคำย่อก็ใช้ตัวอักษรใหญ่เพียงบางตัวอักษร เช่น PhD = Doctor of Philosophy (ปรัชญาดุษฎีบัณฑิต หรือผู้ที่ได้รับปริญญาเอก)
5. ใช้เพื่อเน้นคำ
ในกรณีนี้ผู้เขียนจงใจไม่เขียนตามหลักข้างต้นเพื่อเน้นคำ กลุ่มคำ หรือประโยคโดยการเขียนตัวอักษรใหญ่ทั้งหมด เช่น HELP! (ช่วยด้วย) STOP! (หยุดนะ) เมื่อลองเปรียบเทียบกับการเขียนแบบปกติ Help! Stop! จะเห็นว่าให้ความรู้สึกต่างกันเวลาอ่าน
การใช้ตัวอักษรใหญ่ทั้งหมดอ่านแล้วให้ความรู้สึกเหมือนเป็นการตะโกน ดังนั้นจึงไม่ควรเขียนตัวอักษรใหญ่ติดกันยาวๆ โดยไม่จำเป็น แบบนี้ I’M SO HAPPY TODAY. I GOT PROMOTED AND WON THE £14 MILLION LOTTERY JACKPOT. จะเห็นว่าอ่านยากและดูไม่สุภาพ ทั้งยังอาจทำให้ผู้อ่านรำคาญอีกด้วย
ลองทบทวนหลัก 5 ข้อนี้แล้วเอาไปใช้กันดูครับ จริงๆ แล้วการใช้ capital letter ยังมีหลักยิบย่อยอีกหลายข้อ ดังนั้นเพื่อนๆ ควรจะอ่านข่าวหรือบทความภาษาอังกฤษเยอะๆ และสังเกตว่า capital letter ต้องใช้ในกรณีไหนบ้าง จะได้เขียนได้ถูกต้อง (และคนอ่านไม่แอบบ่นในใจ)
ABC SONG | เพลง ABC สำหรับเด็กฝึกร้อง | การ์ตูนน่ารัก ดูเพลิน สำหรับเด็กอนุบาล
ช่องเพลงเด็ก
สนับสนุนพัฒนาการเด็กไทย
เพื่อให้เรียนรู้เกี่ยวกับ เพลง และ สัตว์ ต่างๆ
เป็ด ลิง กบ ช้าง เต่า แมงมุม
เราทำเป็นเพลงออกมามากมายเพื่อให้เรียนรู้
ผ่านเพลงได้ง่าย ส่งเสริมพัฒนาการ และอารมณ์
ของเด็กไทย มีทั้งเพลงช้าง เพลงเป็ด เพลงเต่า
เพลงกบเอยทำไมจึงร้อง เพลงรถไฟ เพลงแมงมุมลาย
เพลงหนอนผีเสื้อ เพลงลิงเจี๊ยก เจี๊ยก และยังมี
เพลงสำหรับกล่อมนอน เพลงฟังก่อนนอน
เพลงกล่อมเด็กอีกด้วย ทั้งเพลง นกขมิ้นเหลืองอ่อน
เพลง เจ้านกกาเหว่าเอย อีกทั้งเพลงพื้นบ้าน
ก็มีให้ฟังเพื่อร่วมอนุรักษ์วัฒนธรรมพื้นบ้านสืบไป
เช่น เพลงรีรี ข้าวสาร เพลงแม่งูเอ๋ย กินน้ำบ่อไหน
ทั้งเด็กอนุบาล เด็กก่อนวัยเรียน เด็กปฐมวัย
จะได้เรียนรู้ไปพร้อมๆกัน
เพลงเด็ก ช่องเรา เป็น เพลงฮิต ที่ได้รับความนิยม
เป็น เพลงเด็กอนุบาล มีทั้งเพลงไทย และเพลงสากล
เรามี เพลงภาษาอังกฤษ ให้เด็กได้เรียนรู้ด้วย
เพลงเด็ก เพลงฮิต เพลง
นอกจากการดูบทความนี้แล้ว คุณยังสามารถดูข้อมูลที่เป็นประโยชน์อื่นๆ อีกมากมายที่เราให้ไว้ที่นี่: ดูความรู้เพิ่มเติมที่นี่

คำศัพท์ภาษาอังกฤษ เรื่องสัตว์ต่างๆ พร้อมวีดีโอรูปภาพและคำอ่าน | เหมาะสำหรับอนุบาลและเด็กเล็ก
คำศัพท์ภาษาอังกฤษ ในหมวดสัตว์ต่างๆ พร้อมวีดีโอรูปภาพและคำอ่าน | เหมาะสำหรับอนุบาลและเด็กเล็ก
เพื่อเสริมทักษะความรู้และประสบการณ์ใหม่ๆ
วิชาการทั้ง คณิตศาสตร์ ภาษาไทย วิทยาศาสตร์ และอื่นๆๆอีกมากมาย
อย่าลืมกดติดตาม Subscribe WAWA kids art กันนะค่ะ
เกมทายประโยชน์ของสัตว์ตามคำใบ้ https://youtu.be/YpSoUZLTOv0
เกมทายสัตว์พาหะนำโรคตามคำใบ้ https://youtu.be/L0AMS3lsg8Y
เล่นทำอักษร ก ไก่ ฮ นกฮู ด้วยแป้งโด การ์ตูนน่ารักๆ หัดอ่าน พยัญชนะไทย | Learn Thai Alphabet https://youtu.be/bxRPh7p_z24
Play ice cream cups, learn colors, count numbers.เล่นถ้วยไอสครีม เรียนรู้สี นับเลข คำศัพท์ภาษาอังกฤษ https://youtu.be/ya60cjKLCVg
Learn color through art Win surprise eggs. เรียนรู้สีผ่านงานศิลปะ ลุ้นไข่เซอร์ไพรส์ เรียนรู้คำศัพท์ https://youtu.be/4feixRAqFdY
เกมทายพืชผักสวนครัวตามคำใบ้ https://youtu.be/utGeGU2sVUA
เสียงสัตว์ 50 เสียง พร้อมวีดีโดรูปภาพประกอบ https://youtu.be/ysWyXa3sHVo

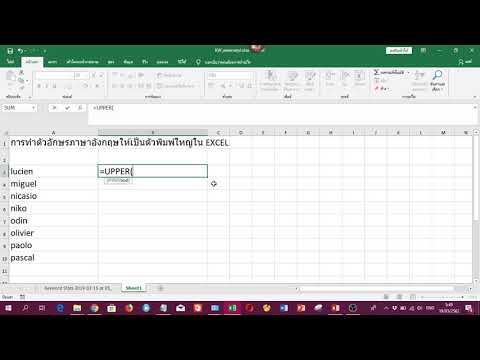
การทำตัวอักษรภาษาอังกฤษให้เป็นตัวพิมพ์ใหญ่ใน EXCEL แบบรวดเร็ว
การทำตัวอักษรภาษาอังกฤษให้เป็นตัวพิมพ์ใหญ่ใน EXCEL แบบรวดเร็ว เป็นวิดีโอที่จะมาแนะนำผู้ที่ใช้โปรแกรม Excel มือใหม่ให้สามรถทำตัวอักษรที่มีอยู่ในเซลล์ของ Excel ให้เป็นตัวพิมพ์ใหญ่แบบง่ายๆและรวดเร็ว ลองๆฝึกทำตาวิดีโอดูนะครับ
อักษรตัวพิมพ์ใหญ่ Capitalization Rule ใช้ตอนไหนบ้าง | Eng ลั่น [by We Mahidol]
การเขียน Writing ในรายงานหรือเรียงความภาษาอังกฤษนั้น เรามักไม่แน่ใจว่าเมื่อไหร่เราควรใช้ตัวพิมพ์เล็กหรือตัวพิมพ์ใหญ่ดี การเขียนแบบไหนถึงเป็นการเขียนที่ถูกต้อง วันนี้พี่คะน้า รุ่นพี่วิทยาลัยนานาชาติ ม.มหิดล จะมาบอกหลักการการใช้ Capitalization Rules รวมถึงข้อยกเว้นต่าง ๆ ที่แสนจะเข้าใจง่ายเอาไปใช้ได้เลย เพื่อการเขียน Writing ที่ถูกต้อง และอาจสามารถเพิ่มคะแนนการเขียน Writing ได้อีกด้วยนะ
CapitalizationRules Engลั่น WeMahidol Mahidol
YouTube : We Mahidol
Facebook : http://www.facebook.com/wemahidol
Instagram : https://www.instagram.com/wemahidol/
Twitter : https://twitter.com/wemahidol
TikTok : https://www.tiktok.com/@wemahidol
มหาวิทยาลัย มหิดล Mahidol University : https://www.mahidol.ac.th/th/
Website : https://channel.mahidol.ac.th/
![อักษรตัวพิมพ์ใหญ่ Capitalization Rule ใช้ตอนไหนบ้าง | Eng ลั่น [by We Mahidol]](https://i.ytimg.com/vi/SMbETdtOKyU/maxresdefault.jpg)
ตัวอักษรภาษาอังกฤษ A-Z (ตัวพิมพ์ใหญ่)
++ ตัวอักษรภาษาอังกฤษ AZ (ตัวพิมพ์ใหญ่) ++
ตัวอักษรภาษาอังกฤษ AZ (ตัวพิมพ์ใหญ่)
1. A (เอ)
2. B (บี)
3. C (ซี)
4. D (ดี)
5. E (อี)
6. F (เอฟ)
7. G (จี)
8. H (เอช)
9. I (ไอ)
10. J (เจ)
11. K (เค)
12. L (แอล)
13. M (เอ็ม)
14. N (เอ็น)
15. O (โอ)
16. P (พี)
17. Q (คิว)
18. R (อาร์)
19. S (เอส)
20. T (ที)
21. U (ยู)
22. V (วี)
23. W (ดับเบิ้ลยู)
24. X (เอ็กซ์)
25. Y (วาย)
26. Z (ซี หรือ แซท)
++ จัดทำโดย Por Pure Channel ++
ฝากกด Like กดแชร์ คลิปวีดีโอ และกด Subscribe ด้วยจร้า
จะอัพคลิปเรื่อยๆ
Channel : https://www.youtube.com/channel/UCuxFOCWjUZ7PxmzBaxialBQ
Subscribe : https://www.youtube.com/channel/UCuxFOCWjUZ7PxmzBaxialBQ?sub_confirmation=1

นอกจากการดูบทความนี้แล้ว คุณยังสามารถดูข้อมูลที่เป็นประโยชน์อื่นๆ อีกมากมายที่เราให้ไว้ที่นี่: ดูวิธีอื่นๆMAKE MONEY ONLINE
ขอบคุณมากสำหรับการดูหัวข้อโพสต์ ตัวพิมพ์ใหญ่ ภาษาอังกฤษ